Causal masking
Create attention masks to prevent the model from seeing future tokens during autoregressive generation.
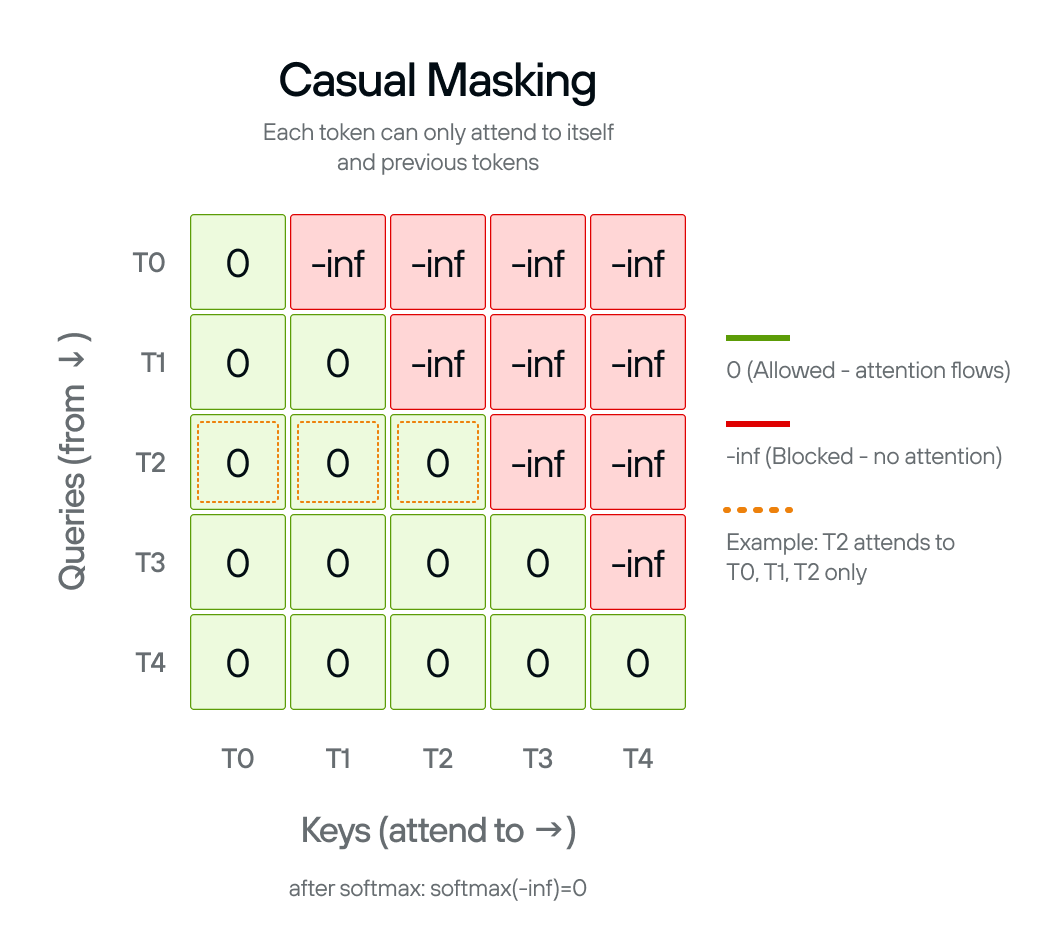
Self-attention, without any constraint, lets every token attend to every other token. GPT-2 generates text left-to-right, so each token must only condition on positions before it. The causal mask enforces this constraint at two distinct points in inference:
Prefill (processing the prompt): the full prompt is encoded in one parallel pass. Without a mask, later tokens in the prompt would influence earlier ones, producing attention scores that differ from what the model learned: corrupted representations from the start.
Decoding (generating new tokens): in principle, generating a single token at the end of a sequence means no future tokens exist to mask. The original GPT-2 architecture has no KV cache, so the full growing sequence is reprocessed on every step and the mask is applied on every forward pass.
The causal_mask() function creates a
mask matrix that sets
attention scores to -inf for future positions. After softmax, -inf becomes
zero probability, blocking information flow from later tokens.

The mask pattern
The mask is lower-triangular: each token can attend to itself and all earlier tokens, but not anything to its right:
- Position 0 attends to: position 0 only
- Position 1 attends to: positions 0–1
- Position 2 attends to: positions 0–2
- And so on…
The mask shape is (sequence_length, sequence_length + num_tokens). The extra
num_tokens dimension is for
KV cache compatibility: during
generation, cached keys and values from earlier tokens can be attended to
without recomputing them.
causal_mask()
The function uses the @F.functional decorator, which converts it to a MAX
graph operation that can be compiled and optimized.
The implementation creates a scalar -inf tensor, broadcasts it to the full
mask shape, then uses F.band_part to zero out the upper triangle
(num_upper=0, exclude=True keeps zeros on and below the diagonal, -inf
above):
@F.functional
def causal_mask(
sequence_length: DimLike,
num_tokens: DimLike,
*,
dtype: DType,
device: Device,
) -> Tensor:
n = Dim(sequence_length) + num_tokens
mask = Tensor(float("-inf"), dtype=dtype, device=device)
mask = F.broadcast_to(mask, shape=(sequence_length, n))
return F.band_part(mask, num_lower=None, num_upper=0, exclude=True)
The scalar -inf tensor is constructed with explicit dtype and device
arguments rather than letting MAX infer them. Passing dtype pins the mask to
exactly the same precision as the rest of the computation. Explicit device
placement ensures the scalar is allocated on the correct device from the start,
consistent with the rest of the graph.
Dim(sequence_length) + num_tokens computes the total width of the mask using
symbolic dimension arithmetic, which lets the compiled graph handle variable
sequence lengths without recompilation.
Next: Multi-head attention uses this mask inside the attention mechanism.